Why do we care about Concurrency?
Because if we look around ourselves do we see a world doing things sequentially (1 step at a time)or do we see a world doing lots of things independently and interacting with each other? Now this is what concurrency is. Given that our surrounding and universe is concurrency. Let’s see how we can model concurrency in our Software and Programming.

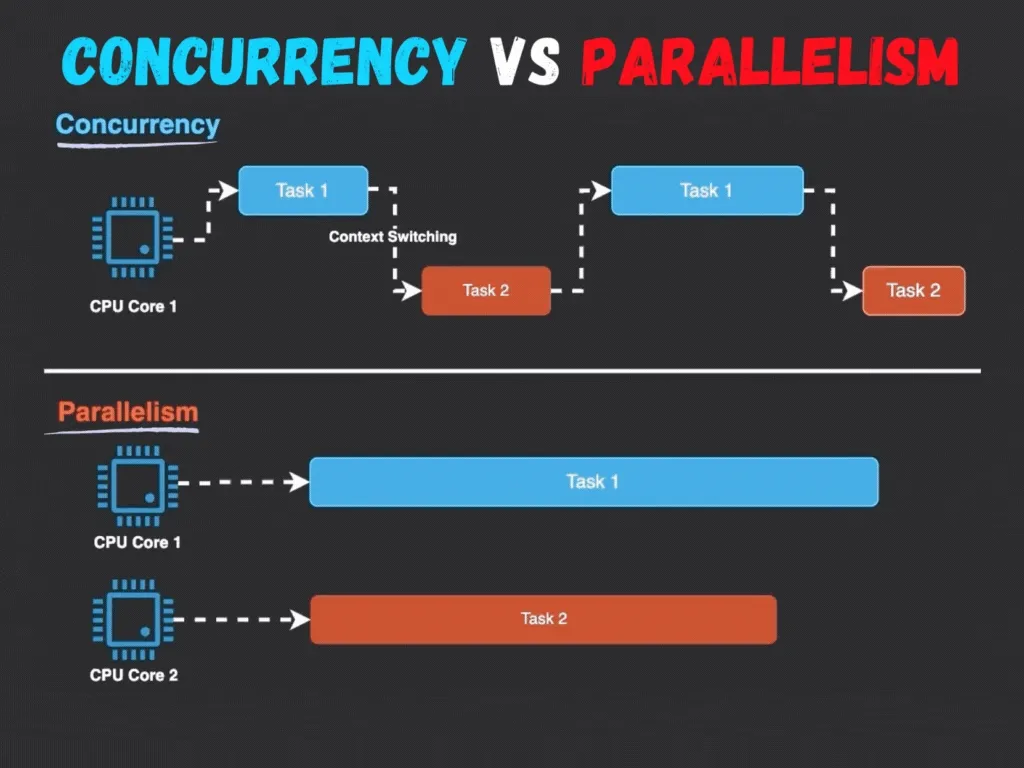
Concurrency vs Parallelism
A concurrent system is extensible to parallelism, but not the other way around
Concurrency can be seen as programming as a the composition of independently executing processes.
Parallelism as a simultaneous execution of (possibly related) computations.
Go as a language has a different approach for dealing with concurrency. In Java, we have threads and an executor framework, but there we use shared memory to communicate between two threads. But Go has different approach to it, it provides goroutines which are lightweight threads, and provide channels to synchronize between various goroutines. And go by this following philosophy:
Do not communicate by sharing memory; instead, share memory by communicating.
A good GIF to summarise this
Concurrency means, things are just being executed at the same time, like car is moving; traffic lights are changing lights; people walking and pedestrians are crossing roads.
Similarly, concurrency is too many things are being done at a single time. And hence our world is concurrent.
Now in programming construct programming languages can implement concurrency using play-pause; context switching; that single threaded languages do like JS; but some languages provide multiple threads and hence parallelism to top to achieve concurrency. And code which respects parallelism respects concurrency; but if a program is concurrent it does not mean its parallel.
The problem we would be solving:
Read a large text file and do word counting in this large file efficiently with GoLang
Let’s Create Data (Data scientist Vibes)
First, let’s create the data, you can find every code piece I write here in this GitHub repo
Creating a large text file from a small text file.
package main
import (
"fmt"
"io"
"log"
"os"
)
func main() {
// Open the original file for reading
originalFile, err := os.Open("sample.txt")
if err != nil {
log.Fatal(err)
}
defer originalFile.Close()
// Create the output file
outputFile, err := os.Create("larger.txt")
if err != nil {
log.Fatal(err)
}
defer outputFile.Close()
// Get the size of the original file
originalFileInfo, err := originalFile.Stat()
if err != nil {
log.Fatal(err)
}
originalSize := originalFileInfo.Size()
fmt.Printf("original size: %v\n", originalSize)
// Set the desired size of the output file (50 MB)
desiredSize := int64(2 * 500 * 1024 * 1024)
// Calculate the number of times to replicate the content
replicationFactor := desiredSize / originalSize
sizeOfOutput := int64(0)
// Replicate the content of the original file
for i := int64(0); i < replicationFactor; i++ {
// Set the file pointer to the beginning of the original file
_, err := originalFile.Seek(0, 0)
if err != nil {
log.Fatal(err)
}
_, err = io.Copy(outputFile, originalFile)
if err != nil {
log.Fatal(err)
}
sizeOfOutput += originalSize
}
// Truncate the output file to the desired size
if sizeOfOutput > desiredSize {
err = outputFile.Truncate(desiredSize)
if err != nil {
log.Fatal(err)
}
}
log.Println("File generated successfully!")
}Just have a sample.txt file in your directory that can be of any size, with the above code we are creating another file named larger.txt, and copying the content of sample.txt into larger.txt until the desired size is not achieved. And at the last, if larger.txt is greater than the desired size we are truncating the larger.txt. So this is how you can create a file of size 1 GB, 20 GB from a 10 KB txt file. That being said you can verify the contents of large.txt by reading its last n lines using tail -10 larger.txt , make sure it has readable content, not something gibberish or binary.
Simple Non Concurrent Code
So let’s first write simple non-concurrent GoLang code to read this file. Complete the code here
func main() {
// calculate the time
startTime := time.Now()
file, err := os.Open(fileName)
if err != nil {
log.Panicf("error in reading file %v", err)
}
defer func(file *os.File) {
err := file.Close()
if err != nil {
panic("Error in closing the file")
}
}(file)
scanner := bufio.NewScanner(file)
wordHashMap := make(map[string]int)
for scanner.Scan() {
line := scanner.Text()
eachWords := strings.Split(line, " ")
for _, word := range eachWords {
if word != "" {
word = strings.ToLower(word)
wordHashMap[word]++
}
}
}
if err := scanner.Err(); err != nil {
log.Panicf("scanner got error: %v", err)
}
// end time
elapsedTime := time.Since(startTime).Milliseconds()
println("Time elapsed in milliseconds: ", elapsedTime)
WriteResultsToFile(wordHashMap)
}In the above code, we opened a file, read it line by line and split words based upon “ ”, and created a hashmap from it that stores each word and its corresponding counts. Given that my file was 1 GB
console output Time elapsed in milliseconds: 8039
Concurrent code for file reading
So the idea behind writing this concurrent code would be the following:
We would create n goroutines that would read files in batches and emit each word in channels. And we would be collecting each word from the channel, and then updating the hashmap accordingly. Simple right, one thing that needs to be taken care of since we are reading a file in batches is that we don’t read half words or a word should let be completed before a batch is marked as read. And if a batch starts with characters, ignore it, and start with the next word. Complete code here
func main() {
// calculate the time
startTime := time.Now()
// A waitgroup to wait for all go-routines to finish.
wg := sync.WaitGroup{}
// This channel is used to send every read word in various go-routines.
channel := make(chan string)
// A dictionary which stores the count of unique words.
dict := make(map[string]int64)
// Done is a channel to signal the main thread that all the words have been
// entered in the dictionary.
done := make(chan bool, 1)
// Read all incoming words from the channel and add them to the dictionary.
go func() {
for s := range channel {
dict[s]++
}
elapsedTime := time.Since(startTime).Milliseconds()
println("Time elapsed in milliseconds: ", elapsedTime)
WriteResultsToFile(dict)
// Signal the main thread that all the words have entered the dictionary.
done <- true
}()
// Current signifies the counter for bytes of the file.
var current int64
fileInfo, err := os.Stat(fileName)
if err != nil {
panic("Error getting file info")
}
fileSize := fileInfo.Size()
numWorkers := runtime.NumCPU()
limit := fileSize / int64(numWorkers)
// Limit signifies the chunk size of file to be proccessed by every thread.
// var limit int64 = 300 * mb
for i := 0; i < numWorkers+1; i++ {
wg.Add(1)
go func(i int, current int64) {
read(current, limit, fileName, channel)
fmt.Printf("\n%d th thread has been completed\n", i)
wg.Done()
}(i, current)
// Increment the current by 1+(last byte read by previous thread).
current += limit + 1
}
// Wait for all go routines to complete.
wg.Wait()
close(channel)
// Wait for dictionary to process all the words.
<-done
close(done)
}In the above code what we are doing is:
We need a mechanism such that if only all goroutines are done with reading their part of the file chunk, then only we would process the final results or exit the program. So to achieve this we use waitGroup in Go, which is incremented and decremented by goroutine when they start their work and then decrements the same when the work is done. We do waitGroup.wait() in the main function, waiting for waitGroup to be 0 again
Given the same 1 GB file we got the output as
Time elapsed in milliseconds: 73037

This is very bad than a simple approach. Why it happened?, is concurrency evil?
This can be explained with the fact that since all goroutines pushed their data into 1 and only 1 channel, and bottle neck was 1 channel. What if we can multiple channels? Maybe we can do better.
One more thing, creating more and more goroutines does not solve the problem, try it yourself, if you increase the workers here, it might take more time. I tried that workers = 5, took 40 seconds on an average, but workers = 8 took 70 seconds. 😂
Another concurrency design
In this approach, we would do something like map reduce, instead of all coroutines sending each word which would bottleneck the main goroutine with so many flooded words, we can ask each coroutine to return an intermediate hashmap, and in the main goroutine, we would combine these all hashmaps to one hashmap
Full code here
func main() {
// calculate the time
startTime := time.Now()
file, err := os.Open(fileName)
if err != nil {
log.Panicf("error in reading file %v", err)
}
defer func(file *os.File) {
err := file.Close()
if err != nil {
panic("Error in closing the file")
}
}(file)
scanner := bufio.NewScanner(file)
wordHashMap := make(map[string]int)
for scanner.Scan() {
line := scanner.Text()
eachWords := strings.Split(line, " ")
for _, word := range eachWords {
if word != "" {
word = strings.ToLower(word)
wordHashMap[word]++
}
}
}
if err := scanner.Err(); err != nil {
log.Panicf("scanner got error: %v", err)
}
// end time
elapsedTime := time.Since(startTime).Milliseconds()
println("Time elapsed in milliseconds: ", elapsedTime)
WriteResultsToFile(wordHashMap)
}And hurrah this is fast 🎉
Time elapsed in milliseconds: 2572
Conclusion
We realised that world is concurrent, and hence it’s important to simulate the same behaviour in our code as well when solving real-world problems
- Created 1 GB file from 2 MB file 🔥
- Wrote a simple GoLang code to read 1 GB file, time was around 8 seconds
- Then wrote a concurrent Golang code, to read the file in chunks it took 70 seconds because the concurrent model was BAD, it was bottlenecking the 1 single hashmap.
- Then wrote another concurrent model which was inspired by what essentially map-reduce does. Get intermediate results from each goroutine and then, at last, combine them
Find everything here
If you found this helpful, please give a clap and lets connect on Twitter and Linkedin